Veeam: A technical deep dive into Veeam Backup for Salesforce
A few days ago we announced general availability of the new Salesforce solution, Veeam Backup for Salesforce, aiming to help companies eliminate the risk of losing Salesforce data and metadata. But why backup Salesforce? If you don’t believe you need to back it up, read this first. While it’s officially a v1 release, I’d like to point out that we’ve been playing with Salesforce data synchronization internally for several years now, until we decided to package our knowledge into a software product. With this new product launch, I’d like to talk more about Veeam Backup for Salesforce’s technical aspects, as well as shed some light on interesting capabilities and architectural decisions we made.
Architecture
Unlike other solutions on the Salesforce data protection market, all of them SaaS offerings, we decided to go with a traditional deployment model and here is why:
- Control your data. We’ve heard from customers that they cannot host their most critical business data in a location, managed by a third party. This simply does not fit their security model and compliance requirements. How do you know if the data is handled properly? Who has access to this data?
That is why Veeam Backup for Salesforce deployment, security and data is fully managed by the customer. The package can be installed on-premises or in the cloud, and the company will always retain access to the data as there is no SaaS vendor involved in the backup process.
To run this product, you will need:
- Linux server (RHEL 7/8 – compatible) to install a package there. For example, for our labs and sandboxes we are using AWS EC2 t3.xlarge instances (4 CPU, 16 GB RAM), but minimal requirements are more modest. Pay attention to the memory here whenever you add more Salesforce instances. Each backup worker consumes additional resources as it runs.
- A data volume for the Salesforce file and metadata backup. Look at your Used File Space in Salesforce and provision three times bigger volume to retain the data. Also, it is a good idea to have the data mounted separately, so you can re-mount this to a new server if needed (upgrade, maintenance).
- PostgreSQL 12-14 server where the Salesforce data from all objects will be stored. For testing and flexibility reasons, I’m using AWS RDS Aurora (PostgreSQL compatible) with a db.r6g.2xlarge instance (8 CPU, 64 GB RAM). This provides me enough memory to build indexes for larger tables (50+M rows) and enough IOPS for making backups and restores at comfortable speeds. But, hey, it’s my huge test environment with 1B+ records to back up.
Since we have kept the multi-organization environment in mind, all of the data and file repositories are segregated. File and metadata storage for each Salesforce organization is isolated, as well as the data storage — each organization would need a separate database to run. There is one more thing, in our labs the installation and configuration of Veeam Backup for Salesforce is completely scripted and provisioned via the ansible template. I’m sure VCSPs would appreciate having this ability to deploy a new instance from the code. I may cover this in a future post.
Now, let me use a product diagram to illustrate that architecture in simple icons and arrows.

As for the product installation, there is nothing special about this package. According to the Salesforce backup user guide, you can run a script that will do almost all of the work for you. You don’t need to be a Linux expert to do this.
Backup
Within this product’s initial configuration, you’ll already have the first Salesforce organization added and the first policy automatically created. We’re using Salesforce-native APIs to pull out everything that can be pulled out, and after the first full backup, will be having forever incremental runs. Now, it’s a good time to take a look at backup policy options and default settings. Go ahead and edit them as you see fit.
- Custom backup schedule. For example, you may want to enable a custom schedule for your most important objects (ex: accounts, contacts, opportunities). As the default option is Daily, it might be unacceptable in dynamic environments where changes are being written to system every few minutes. Create a custom schedule (ex. 15 minutes) and assign it to desired objects individually.

- Set API limits. You probably have tons of integrations and managed packages that consume daily API calls. If you run out of API calls, all those integrations will stop — that would be a big problem, wouldn’t it? With API limits, Veeam Backup for Salesforce will check the API calls available before launching a backup policy and during the policy as well and halt its operations if the threshold is reached, so you remain operational.
Speaking of Salesforce APIs, the backup service will detect when to use Bulk API vs Rest API or SOAP. Depending on the type of the object and the increment size, the optimal API will be used.
Now that we’ve looked at backup, let’s discuss the true star in this solution: recovery.
Recovery
You’re going to notice four different data recovery types right when you launch a corresponding wizard. Just pick whatever achieves your desired outcome and off you go, the types are self-explanatory.

- Compare record versions. As you back up your data and changes are detected, the complete snapshot of each record will be saved independently into the history table for this object. During restore, you can choose the version you would like to restore from. From a UI perspective, it’s similar to Veeam Explorer for Microsoft Active Directory functionality, as the recovery wizard helps you visually compare the backup state of the object with its production state and see the changes so you can act accordingly.
- Hierarchy recovery. Another key capability will help you recover from an incorrect merge or issue with cascading deletion or update. Select the object(s) in question and enable the toggle “restore objects hierarchy,” so you can see inside hierarchy branches at a depth you need. Go ahead and restore the entire record’s tree to bring all dependent objects and their relationships back to the desired state.
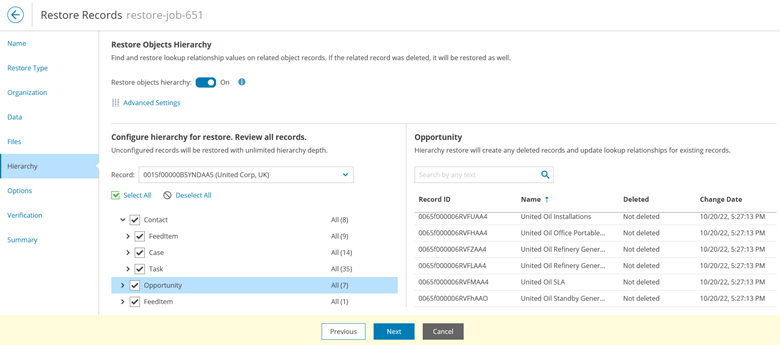
- Turn off automation. As there’s a good chance your environment has some advanced business logic and automated rules, which can potentially block restores or trigger undesirable side processes during the data restoration, you have an option to remedy that. You can instruct the product to disable (permanently or temporarily) all triggered automation for the user that is executing the backup and restore operation. This should make recovery an easier process and result in a better recovery success rate.
Conclusion
Besides all the backup and restore capabilities, we also have something to make the life of a backup (Salesforce) administrator easier. For example, they can make use of a few predefined real-time alerts for backup, recovery, licensing and connection issues, and get notified about those events via email or even slack.
They can also share access to the backup console and assign users various roles (administrator, backup operator, restore operator and viewer), being very specific about the management scope (only for this organization, this specific company, a combination of those or everything at once). Those roles can be assigned to the users of Azure Active Directory in a granular way, and the latter will serve as an identity provider for anyone accessing the console, so it’ll be very appreciated by IT and security teams in your company.
This was a quick look under the hood of Veeam Backup for Salesforce. We truly believe this product, based on core Veeam principles, is going to deliver leading data protection practices to your Salesforce environment, so you can always focus more on company business.
Source: Veeam
